项目地址:https://github.com/zhang3399/Single-phase_load_recognition
# 项目简介
在一个单相电力线上,对电压电流数据进行录波,从波形数据上提取有效信息,通过建模 - 训练的方式,识别出电力线上正在使用的电器有哪些。
utils/datasets.py: 将数据集处理为输入特征和学习标签utils/models.py: 定义 LSTM 模型config/params.py: 配置模型参数,存储路径,识别目标等results/train.py: 训练模型,验证集识别效果predict.py: 使用训练好的模型进行预测
# 数据集说明
- 使用公开数据集:NILM 国内电器设备数据,下载地址:https://gitcode.com/Universal-Tool/47e33/?utm_source=article_gitcode_universal&index=top&type=card
- 数据集结构:一个 Excel 文件包含多张表,每张表记录一个设备的电压、电流等以及操作状态记录。
数据集包含了以下核心结构:
- 设备信息:
| 设备 ID | 设备类型 | 工作参数 |
|---|---|---|
| YD1 | 奥克斯风扇 | 220V, 60W |
| YD2 | 美的微波炉 | 220V, 输入 1150W, 输出 700W |
| … | … | … |
| YD11 | 创维电视机 | 220V, 50Hz, 150W |
- 设备监测数据:
| 字段 | 说明 | 单位 |
|---|---|---|
| time | ||
| Ic | 电流值 | 0.001 A |
| Uc | 电压值 | 0.1 V |
| PC | 有功功率 | 0.0001kW |
- 周波数据:
| 字段 | 说明 |
|---|---|
| IC001 | 电流周波第 1 采样点 |
| … | … |
| UC128 | 电压周波第 128 采样点 |
- 谐波数据
| 字段 | 说明 | 单位 |
|---|---|---|
| time | ||
| IC02 | 2 次电流谐波含有率 | % |
| … | … | … |
| UC51 | 2 次电压谐波含有率 | % |
- 用电设备操作记录
| 序号 | 时间 | 设备 | 工作状态 | 操作 |
|---|---|---|---|---|
| 1 | 2019-01-01 00:00:00 | YD1 | 开启 | 启动 |
| 2 | 2019-01-01 00:00:30 | YD1 | 关闭 | 关闭 |
| 3 | 2019-01-01 00:00:00 | YD1 | 1 档 | 启动 |
| 4 | 2019-01-01 00:00:30 | YD1 | 2 档 | 关闭 |
| … | … | … | … | … |
# 数据预处理
处理流程:
graph TB | |
A[原始Excel] --> B[时间对齐] | |
B --> C[状态标签编码] | |
C --> D[特征工程] | |
D --> E[训练/测试集分割] |
关键处理步骤:
- 时间对齐:
start_times = [ | |
df_device['time'].min(), | |
df_wave['time'].min(), | |
] | |
end_times = [ | |
df_device['time'].max(), | |
df_wave['time'].max(), | |
] | |
# 最晚开始时间和最早结束时间 | |
common_start = max(start_times) | |
common_end = min(end_times) | |
# 裁剪设备、周波、谐波表到共同时间范围 | |
df_device = df_device[(df_device['time'] >= common_start) & (df_device['time'] <= common_end)] | |
df_wave = df_wave[(df_wave['time'] >= common_start) & (df_wave['time'] <= common_end)] |
- 状态标签编码:(二分类与多分类)
def createLabel(df, output_path='device_encoders.json', multi_class=True): | |
""" | |
创建设备状态标签并保存映射关系 | |
参数: | |
df: 包含设备状态的DataFrame | |
output_path: 映射关系保存路径 | |
multi_class: 是否使用多分类(默认True) | |
""" | |
device_cols = [col for col in df.columns if col.startswith('YD')] | |
device_encoders = {} | |
for device in device_cols: | |
# 获取设备的所有状态 | |
states = sorted(df[device].dropna().unique()) | |
state_count = len(states) | |
if multi_class and state_count > 2: | |
# 多分类映射:为每个状态分配唯一整数 | |
mapping = {state: i for i, state in enumerate(states)} | |
print(f"{device} 状态({state_count}种): {states} → 编码: {mapping}") | |
# 创建多分类标签列 | |
df[f'is_{device}'] = df[device].map(mapping).fillna(-1).astype(int) | |
else: | |
# 二分类映射:关闭→0,其他→1 | |
mapping = {state: (0 if str(state).strip().lower() == "关闭" else 1) for state in states} | |
print(f"{device} 状态({state_count}种): {states} → 二值编码: {mapping}") | |
# 创建二分类标签列 | |
df[f'is_{device}'] = df[device].map(mapping).fillna(-1).astype(int) | |
device_encoders[device] = mapping | |
# 保存映射关系为 JSON 格式 | |
with open(output_path, 'w', encoding='utf-8') as f: | |
json.dump(device_encoders, f, ensure_ascii=False, indent=4) | |
print(f"映射关系已保存到 {output_path}") | |
return df |
二分类映射关系:
{ | |
"YD10": {"1档冷风": 1,"1档热风": 1,"2档冷风": 1, | |
"2档热风": 1,"关闭": 0 | |
}, | |
"YD11": {"关闭": 0,"打开": 1} | |
... | |
} |
多分类映射关系:
{ | |
"YD10": {"1档冷风": 0,"1档热风": 1,"2档冷风": 2, | |
"2档热风": 3,"关闭": 4 | |
}, | |
"YD11": {"关闭": 0,"打开": 1} | |
.... | |
} |
- 特征工程:
对电压、电流、周波和谐波数据与设备状态之间的相关性分析:
分析结果保存在根目录下,考虑问题场景是基于电压电流,识别运行设备,只使用开源数据集的电压电流特征数据作为特征序列。
# 模型搭建
考虑电压电流数据呈时间连续,设备启停在过往与当前时刻的电压电流具有相应的特征变化,因此采用时序模型。
核心:
-
LSTM:长短期记忆网络,擅长处理时间序列数据,能够捕捉时间序列中的长期依赖关系。 -
识别方式:采用i~j组时间序列电流电压数据,识别第j组时间序列下的电器状态,i~j由params.py参数WINDOW_SIZE值控制,即滑动窗口,LSTM 模型学习步长。
# 模型训练
训练说明:
- 二分类
datahandl.py处理:将df = createLabel(df, multi_class=False)改为multi_class=False,将状态标签编码为二分类标签。- 执行
train.py:训练完成后,模型保存在results/train文件中,可执行predict.py进行推理。
- 多分类
datahandl.py处理:将df = createLabel(df, multi_class=True)改为multi_class=True,将状态标签编码为多分类标签。- 执行
train_plus.py:可以训练,但是目前由于数据量不足,泛化能力较差,推理模块predict_plus.py暂时未实现。
方案一: (二分类模型如下)
模型为每个设备配置一个输出头,预测该设备是否在运行。
class ApplianceLSTM(nn.Module): | |
"""多输出电器状态识别LSTM模型""" | |
def __init__(self, input_size, hidden_size, num_layers, num_outputs): | |
super(ApplianceLSTM, self).__init__() | |
# 减少隐藏层大小和层数 | |
self.hidden_size = hidden_size | |
self.num_layers = min(num_layers, 2) # 限制层数 | |
# LSTM 层 - 添加 dropout | |
self.lstm = nn.LSTM( | |
input_size, | |
self.hidden_size, | |
self.num_layers, | |
batch_first=True, | |
bidirectional=False, # 移除双向结构减少复杂度 | |
dropout=0.3 if self.num_layers > 1 else 0 # 层间 dropout | |
) | |
# 简化全连接层 | |
self.fc = nn.Sequential( | |
nn.Linear(self.hidden_size, 32), | |
nn.ReLU(), | |
nn.Dropout(0.4), # 增加 dropout 比例 | |
nn.LayerNorm(32), # 添加批归一化 | |
nn.Linear(32, 16), | |
nn.ReLU() | |
) | |
# 共享特征提取,独立输出层 | |
self.output_layers = nn.ModuleList([ | |
nn.Sequential( | |
nn.Linear(16, 1), | |
nn.Sigmoid() | |
) for _ in range(num_outputs) | |
]) | |
def forward(self, x): | |
# 初始化隐藏状态 | |
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
# LSTM 前向传播 | |
out, _ = self.lstm(x, (h0, c0)) | |
out = out[:, -1, :] # 只取最后一个时间步的输出 | |
# 通过全连接层 | |
out = self.fc(out) | |
# 每个电器一个输出头 | |
outputs = [output_layer(out) for output_layer in self.output_layers] | |
# 合并输出为 [batch_size, num_outputs] | |
return torch.cat(outputs, dim=1) |
方案二:(多输出头的多类别预测)
模型为每个设备配置一个输出头,并根据设备状态数量,设计对应的输出维度。
class ApplianceLSTM_plus(nn.Module): | |
"""支持不同设备不同状态数的多输出LSTM模型""" | |
def __init__(self, input_size, hidden_size, num_layers, states_per_device): | |
super(ApplianceLSTM, self).__init__() | |
self.hidden_size = hidden_size | |
self.num_layers = min(num_layers, 2) | |
self.states_per_device = states_per_device # 每个设备的状态数列表 | |
# LSTM 层 | |
self.lstm = nn.LSTM( | |
input_size, | |
hidden_size, | |
num_layers, | |
batch_first=True, | |
bidirectional=False, | |
dropout=0.3 if num_layers > 1 else 0 | |
) | |
# 共享的全连接层 | |
self.fc = nn.Sequential( | |
nn.Linear(hidden_size, 32), | |
nn.ReLU(), | |
nn.Dropout(0.5), | |
nn.LayerNorm(32), | |
nn.Linear(32, 16), | |
nn.ReLU() | |
) | |
# 为每个设备创建独立的输出层(状态数不同) | |
self.output_layers = nn.ModuleList([ | |
nn.Linear(16, states) for states in self.states_per_device | |
]) | |
def forward(self, x): | |
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(x.device) | |
out, _ = self.lstm(x, (h0, c0)) | |
out = out[:, -1, :] # 取最后一个时间步的输出 | |
out = self.fc(out) | |
# 每个设备独立输出(列表形式,每个元素对应一个设备的 logits) | |
outputs = [layer(out) for layer in self.output_layers] | |
return outputs |
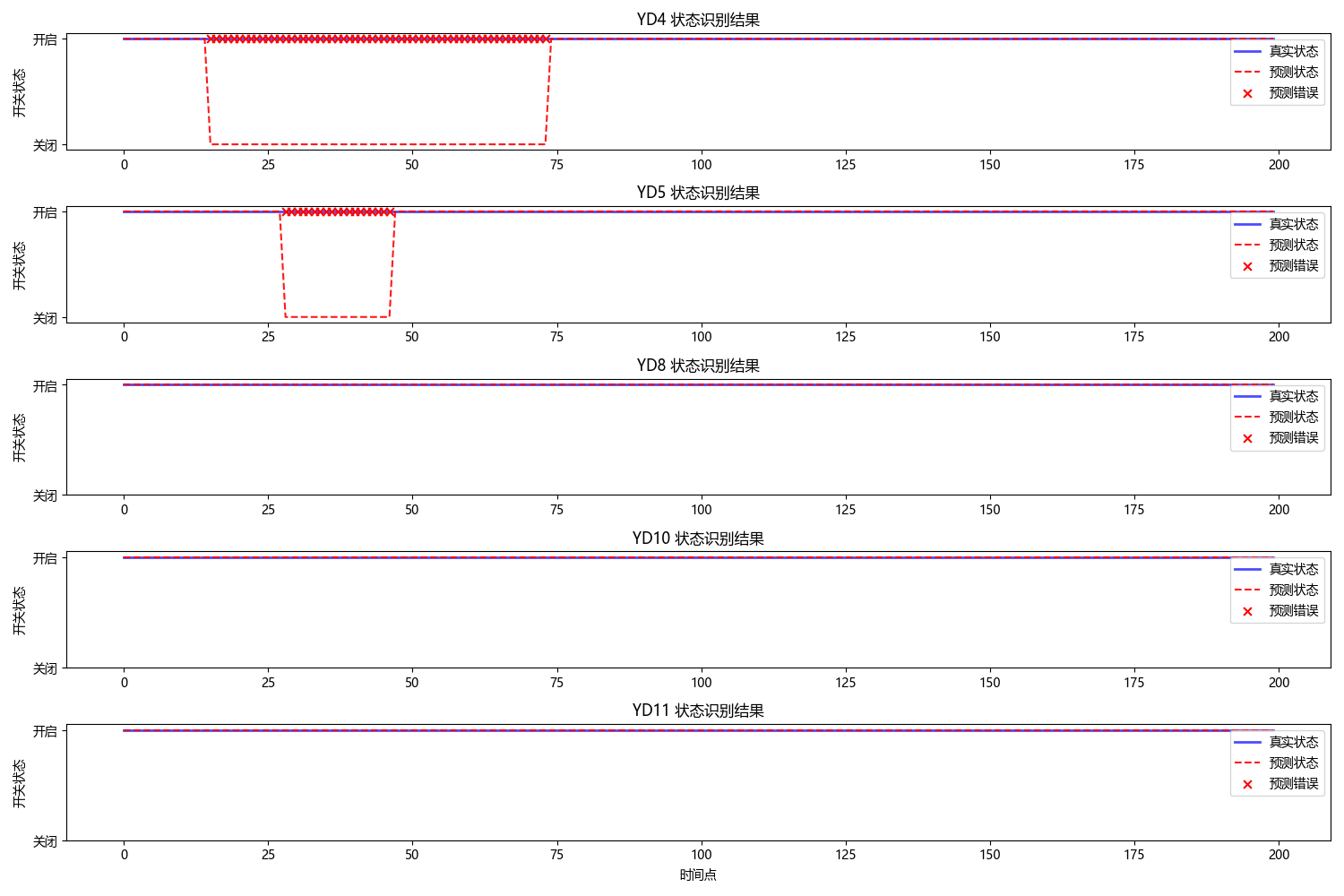
识别结果:
由于数据体量过小,有些过拟合,存在少量将关闭状态识别为开启状态的问题。