tensoRT 是 NVIDIA 推出的一款深度学习推理框架,可以在 GPU 上加速深度学习模型的推理过程。
# 准备工作
安装 tensoRT 需要先安装 CUDA 和 cuDNN。
- CUDA 下载地址:https://developer.nvidia.com/cuda-downloads
- cuDNN 下载地址:https://developer.nvidia.com/cudnn
安装 CUDA 需要注意选择正确的版本,CUDA 版本和 cuDNN 版本需要对应。
# tensoRT 安装
- 查看 CUDA 版本
nvcc --version |

我的是 CUDA 11.1 版本
-
选择 tensoRT 安装版本
tensoRT 官方下载地址:https://developer.nvidia.com/tensorrt/download
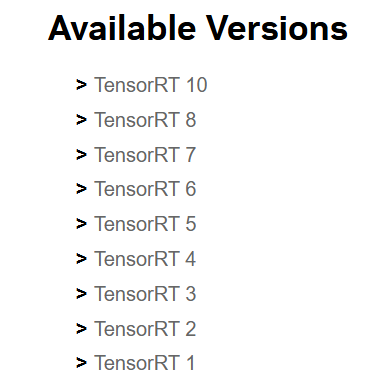
选择对应的安装版本,我是选的8.*版本,7.*版本缺少后续官方最新安装教程的python.wheel文件 -
下载安装包
点击同意协议

选择对应的版本下载,注意支持的 CUDA 版本
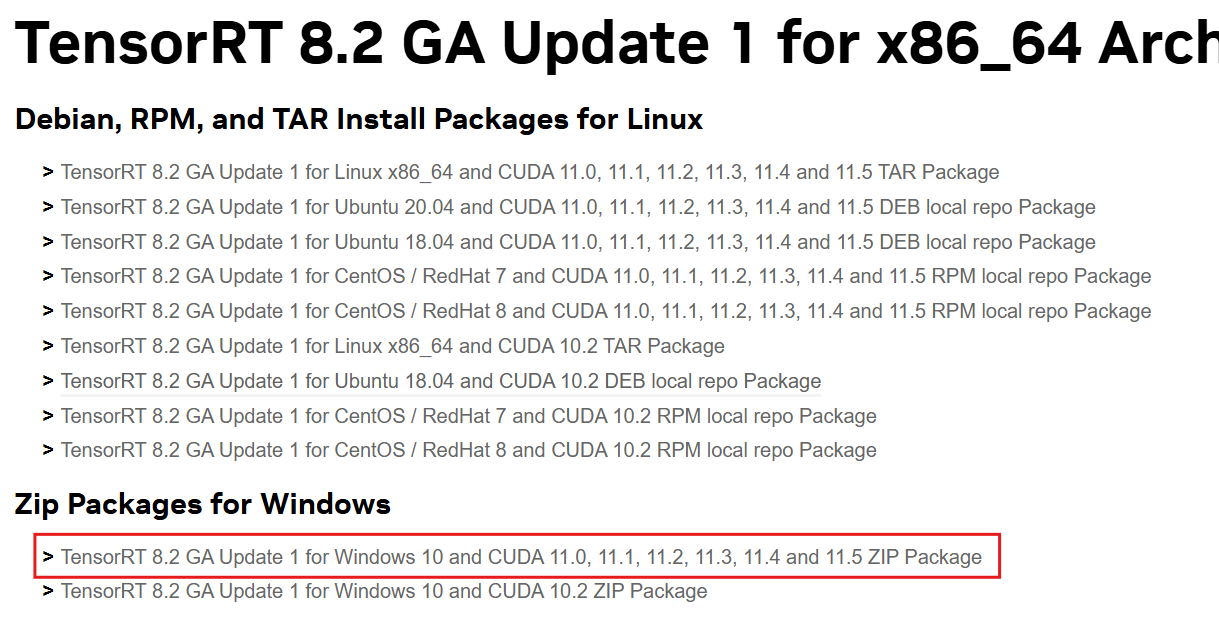
-
添加 TensoRT 库文件到环境变量
- 确认下载路径,将文件中的
lib包文件路径添加到系统环境变量,我的是D:\SoftwareDevelopment\programer\TensorRT-8.2.2.1\lib. - 将解压文件的
bin、include目录文件复制粘贴到CUDA安装目录下的lib\x64、include中,我CUDA安装位置在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.1。
- 安装
TensorRT Python wheel文件
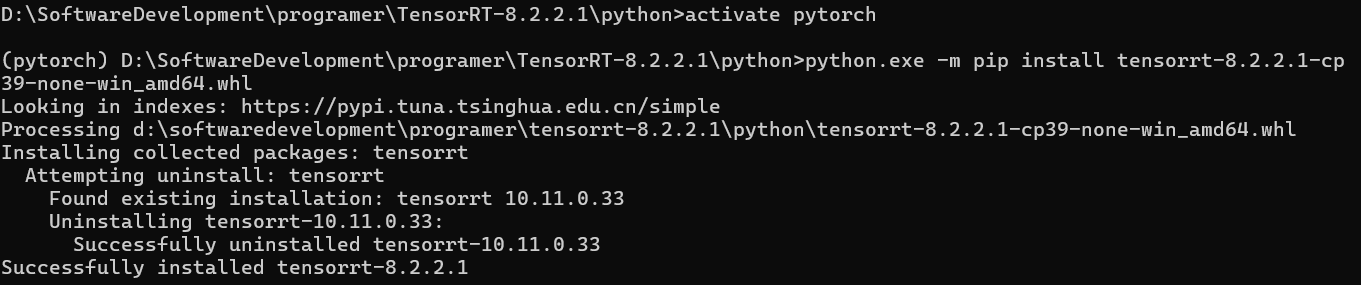
cd 到下载的安装包路径中的 python 路径下,执行以下命令安装:
python.exe -m pip install tensorrt-8.2.2.1-cp39-none-win_amd64.whl |
(注意:cp39 要替换为自己安装 python 解释器的版本,可以终端执行 python -version 查看)
启动 anaconda 虚拟环境,切换到 python3.9 环境,再次执行执行 python.exe -m pip install tensorrt-8.2.2.1-cp39-none-win_amd64.whl :
6. 检验
正常安装完成后,执行以下命令检验,如果输出 8.2.2.1 类似版本,则表示安装成功。
import tensort | |
print(tensort.__version__) |
如果提示错误:
FileNotFoundError: Could not find: nvinfer_10.dll. Is it on your PATH? |
将 tensort 解压文件夹中 lib 目录中的 dll 后缀文件复制到 bin 目录中,重新执行 import tensort 即可。
- 测试案例
官方 python 构建示例:https://docs.nvidia.com/deeplearning/tensorrt/latest/inference-library/python-api-docs.html
下载 resnet18 模型,将 pytorch 模型的 .pt 文件转为 .onnx 文件:
import torch | |
import torchvision.models as models | |
import onnx | |
import onnxruntime | |
# 加载 PyTorch 模型 | |
model = models.resnet18(weights=True) | |
model.eval() | |
# 定义输入和输出张量的名称和形状 | |
input_names = ["input"] | |
output_names = ["output"] | |
batch_size = 1 | |
input_shape = (batch_size, 3, 224, 224) | |
output_shape = (batch_size, 1000) | |
# 将 PyTorch 模型转换为 ONNX 格式 | |
torch.onnx.export( | |
model, # 要转换的 PyTorch 模型 | |
torch.randn(input_shape), # 模型输入的随机张量 | |
"resnet18.onnx", # 保存的 ONNX 模型的文件名 | |
input_names=input_names, # 输入张量的名称 | |
output_names=output_names, # 输出张量的名称 | |
dynamic_axes={input_names[0]: {0: "batch_size"}, output_names[0]: {0: "batch_size"}} # 动态轴,即输入和输出张量可以具有不同的批次大小 | |
) | |
# 加载 ONNX 模型 | |
onnx_model = onnx.load("resnet18.onnx") | |
onnx_model_graph = onnx_model.graph | |
onnx_session = onnxruntime.InferenceSession(onnx_model.SerializeToString()) | |
# 使用随机张量测试 ONNX 模型 | |
x = torch.randn(input_shape).numpy() | |
onnx_output = onnx_session.run(output_names, {input_names[0]: x})[0] | |
print(f"PyTorch output: {model(torch.from_numpy(x)).detach().numpy()[0, :5]}") | |
print(f"ONNX output: {onnx_output[0, :5]}") |
tensoRT 构建引擎:
方式 1:
使用 trtexec 工具
trtexec --onnx=resnet18.onnx --saveEngine=resnet18.engine --float16 |
方式 2:
使用 python 脚本
import tensorrt as trt | |
import numpy as np | |
# 加载 ONNX 模型 | |
onnx_file_path = "resnet18.onnx" | |
onnx_model = trt.OnnxParser.create_network( | |
parser=trt.OnnxParser(network=trt.Network()), # 创建一个 ONNX 解析器 | |
flags=0 # 解析器标志,0 表示默认值 | |
) | |
with open(onnx_file_path, "rb") as model_file: # 打开 ONNX 模型文件 | |
onnx_model.deserialize(model_file.read()) # 反序列化 ONNX 模型 | |
# 创建 TensorRT 引擎 | |
trt_logger = trt.Logger(trt.Logger.WARNING) # 创建一个 TensorRT 日志记录器 | |
trt_builder = trt.Builder(trt_logger) # 创建一个 TensorRT 构建器 | |
trt_builder.max_batch_size = 1 # 设置最大批次大小 | |
trt_builder.max_workspace_size = 1 << 30 # 设置最大工作空间大小 | |
trt_builder.fp16_mode = True # 启用 FP16 模式 | |
trt_builder.int8_mode = False # 禁用 INT8 模式 | |
trt_engine = trt_builder.build_cuda_engine(onnx_model) # 构建 TensorRT 引擎 | |
# 保存 TensorRT 引擎 | |
trt_engine_path = "resnet18.engine" | |
trt_engine.serialize().tofile(trt_engine_path) # 将 TensorRT 引擎序列化为字节流并保存到文件中 |
使用 tensoRT 模型进行推理:
import tensorrt as trt | |
import pycuda.driver as cuda | |
import pycuda.autoinit | |
import numpy as np | |
# 加载 TensorRT 引擎 | |
trt_engine_path = "resnet18.trt" | |
trt_engine = trt.Runtime(trt.Logger(trt.Logger.WARNING)).deserialize_cuda_engine(trt_engine_path) | |
# 创建执行上下文 | |
trt_context = trt_engine.create_execution_context() | |
# 定义输入和输出张量的形状 | |
input_shape = (1, 3, 224, 224) | |
output_shape = (1, 1000) | |
# 分配内存 | |
input_memory = cuda.mem_alloc(trt_engine.get_binding_shape(0)[0] * trt.volume(input_shape)) | |
output_memory = cuda.mem_alloc(trt_engine.get_binding_shape(1)[0] * trt.volume(output_shape)) | |
# 准备输入数据 | |
input_data = np.random.randn(*input_shape).astype(np.float32) | |
# 将输入数据复制到 GPU 内存中 | |
cuda.memcpy_htod(input_memory, input_data) | |
# 执行推理 | |
trt_context.execute_v2(bindings=[int(input_memory), int(output_memory)]) | |
# 将输出数据从 GPU 内存中复制到主机内存中 | |
output_data = np.empty(output_shape, dtype=np.float32) | |
cuda.memcpy_dtoh(output_data, output_memory) | |
# 打印输出结果 | |
print(output_data) |